Apache Kafka: Эффективная обработка потоков данных в реальном времени

Apache Kafka стала стандартом де-факто для обработки потоковых данных в реальном времени. Она позволяет организациям собирать, обрабатывать и анализировать огромные объемы информации, поступающей с различных источников. В этой статье мы подробно рассмотрим архитектуру Kafka, ее основные компоненты и преимущества, а также разберем типичные сценарии использования.
Архитектура Apache Kafka: Ключевые компоненты
Kafka построена на основе распределенной архитектуры, состоящей из нескольких ключевых компонентов:
- Producer (Производитель): Отвечает за отправку данных в Kafka. Производители могут публиковать данные в определенные темы (topics).
- Topic (Тема): Категория, к которой относятся опубликованные сообщения. Темы разделены на партиции.
- Partition (Партиция): Упорядоченная, неизменяемая последовательность сообщений. Партиции распределяются между брокерами.
- Broker (Брокер): Сервер в кластере Kafka, который хранит данные. Брокеры отвечают за обработку запросов на чтение и запись данных.
- Consumer (Потребитель): Получает данные из Kafka. Потребители подписываются на определенные темы и читают данные из партиций.
- Zookeeper: Используется для управления кластером Kafka, координации брокеров и хранения метаданных.
Kafka обеспечивает высокую пропускную способность и отказоустойчивость благодаря распределенной архитектуре и использованию партиций. Каждая партиция может быть реплицирована на несколько брокеров, что обеспечивает сохранность данных в случае отказа одного из брокеров. 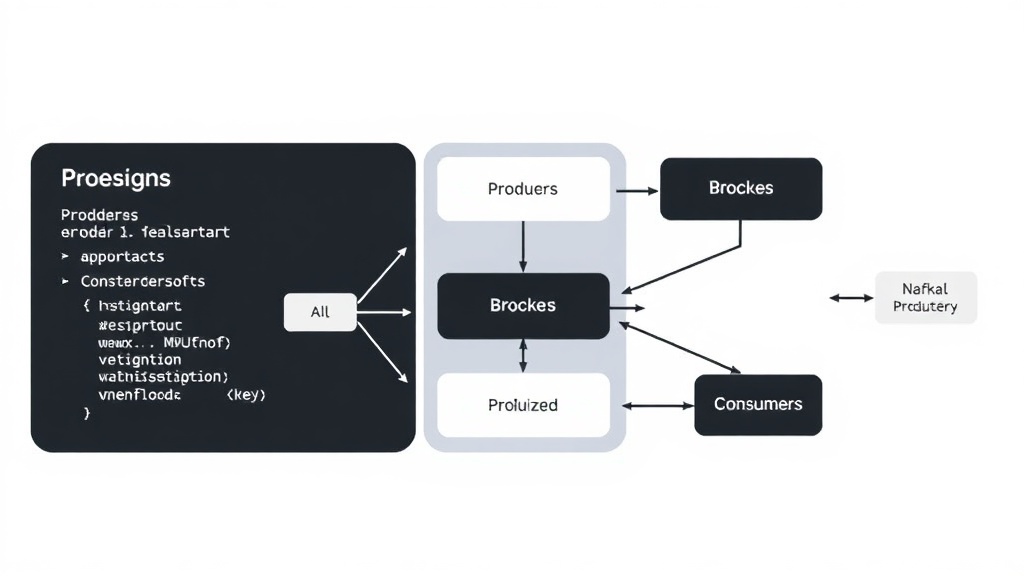
Преимущества использования Apache Kafka
Kafka предлагает ряд преимуществ по сравнению с традиционными системами обмена сообщениями и ETL:
- Масштабируемость: Kafka способна обрабатывать огромные объемы данных, масштабируясь горизонтально путем добавления новых брокеров в кластер. Например, LinkedIn использует Kafka для обработки триллионов сообщений в день.
- Отказоустойчивость: Репликация данных между брокерами обеспечивает высокую доступность и сохранность данных даже в случае сбоев.
- Обработка в реальном времени: Kafka позволяет обрабатывать данные в режиме реального времени, что критически важно для многих современных приложений, таких как мониторинг, аналитика и обнаружение мошенничества.
- Надежность: Kafka гарантирует доставку сообщений, даже в случае сбоев.
- Интеграция: Kafka легко интегрируется с различными системами и платформами, включая Hadoop, Spark, Flink и другие.
Сценарии использования Apache Kafka
Kafka находит применение в различных отраслях и сценариях:
- Сбор логов: Kafka может использоваться для сбора и агрегации логов с различных серверов и приложений. Например, Netflix использует Kafka для сбора и анализа логов для мониторинга производительности и обнаружения проблем.
- Мониторинг: Kafka может использоваться для мониторинга различных систем и приложений в реальном времени. Например, Twitter использует Kafka для мониторинга трендов и событий в реальном времени.
- Потоковая аналитика: Kafka может использоваться для потоковой аналитики данных в реальном времени. Например, Uber использует Kafka для анализа данных о поездках и оптимизации маршрутов.
- Интеграция данных: Kafka может использоваться для интеграции данных между различными системами и приложениями.
- Обработка событий: Kafka может использоваться для обработки событий в реальном времени, таких как транзакции, клики и взаимодействия с пользователем.
FAQ по Apache Kafka
Вопрос: В чем разница между Kafka и RabbitMQ?
Ответ: Kafka предназначена для обработки больших потоков данных с высокой пропускной способностью и отказоустойчивостью, в то время как RabbitMQ больше подходит для более традиционных сценариев обмена сообщениями, где важна гарантированная доставка каждого сообщения.
Вопрос: Как обеспечить безопасность в Kafka?
Ответ: Kafka поддерживает различные механизмы безопасности, включая SSL/TLS для шифрования данных, Kerberos для аутентификации и ACL для авторизации.
Итоги
Apache Kafka – мощный инструмент для обработки потоковых данных в реальном времени. Ее масштабируемая, отказоустойчивая и надежная архитектура делает ее идеальным выбором для широкого спектра приложений, от сбора логов и мониторинга до потоковой аналитики и интеграции данных. Понимание основных принципов работы Kafka и ее компонентов позволяет эффективно использовать ее возможности для решения сложных задач обработки данных.
🤖 Telegram-канал ITOQ AI
Новости ИИ, лайфхаки, промпты и эксклюзивные акции — подпишись чтобы не пропустить!
- Обзоры новых AI-моделей
- Промпты и лайфхаки для нейросетей
- Примеры генерации изображений FLUX
- Промокоды и специальные предложения